Reconfigurable computing
so your SoC can adapt
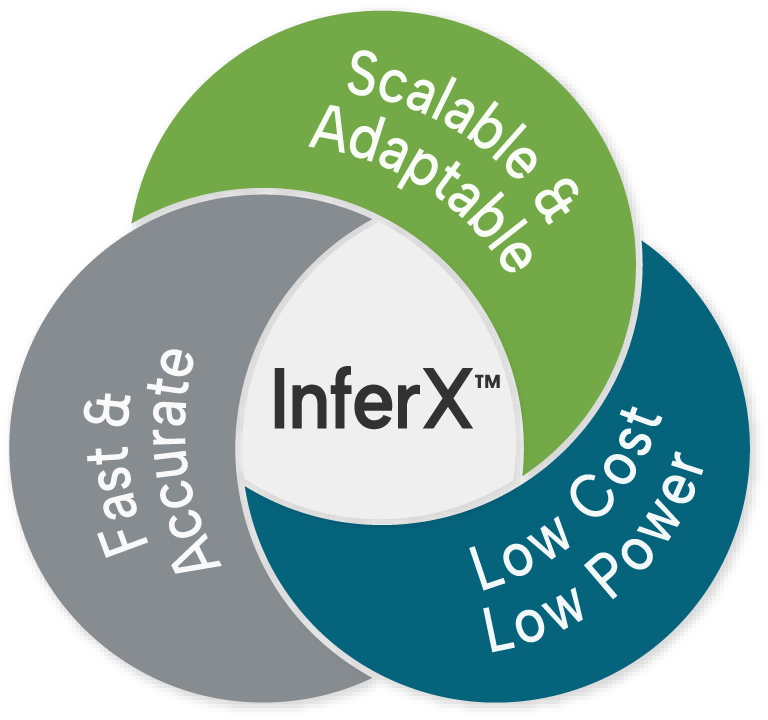
Reconfigurable computing gives you the best combination of the performance of hard-wired with programmability so you can adapt to new needs, protocols, standards, and algorithms.
eFPGA IP is proven in more than 25 chips with many more in design. DSP/AI IP now available: world class performance at a fraction of the cost and power.