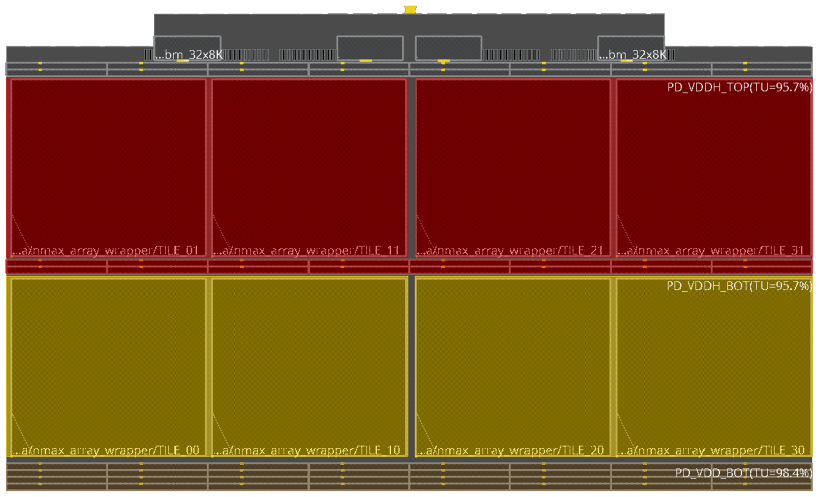
10s of mm2 of InferX in N7/5/3 delivers performance that rivals the best AI chips while maintaining accuracy and flexibility. InferX is 80% hardwired and 100% reconfigurable so it is very efficient.
InferX is a scalable architecture built on the InferX tile to build arrays: N tiles run N times faster.
InferX can run multiple models, even mixing AI and DSP, and reconfigure in a few microseconds for changing workloads.
InferX has the flexibility and the compute to adapt to tough new models over time. We can quickly implement new operators at high efficiency using our programmable architecture.
InferX Gen1 is proven in Silicon. Flex Logix IP is proven in dozens of customers’ chips.
InferX Subsystem
InferX is a Subsystem in your SoC
You determine the process node you need: 16, 12, 7/6, 5/4nm.
You determine the performance you need: we can use more tiles for more throughput.
We deliver an array of InferX tiles, based on your node and performance targets, with an AXI bus interface to your NOC. Other buses are possible.
We handle DFT, MBIST and other physical design considerations.
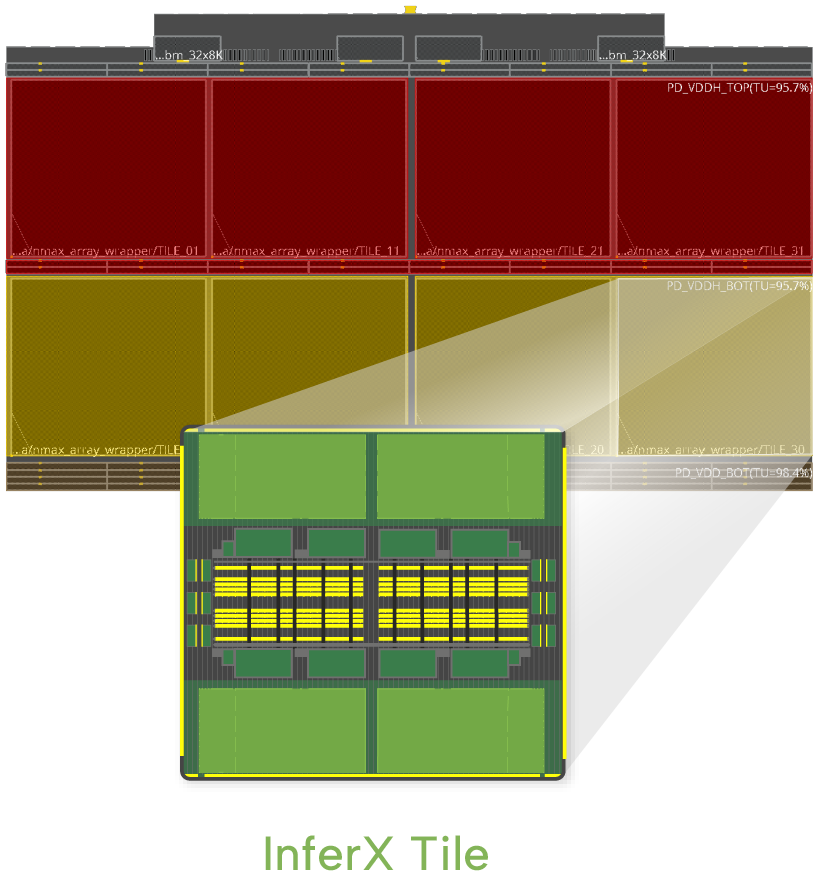
InferX Tile
InferX Compute Tile
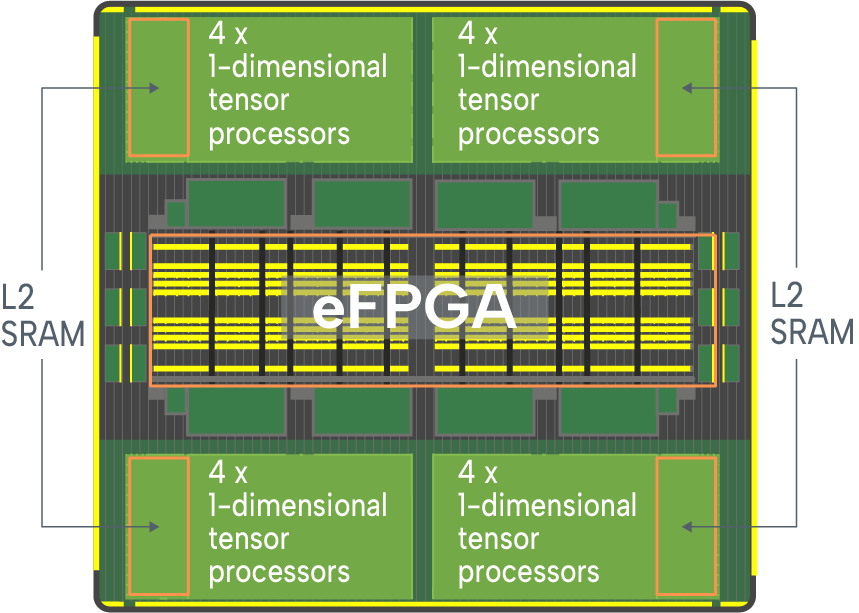
InferX combines hardwired compute blocks with embedded FPGA for fast, programmable control path. It is 80% hardwired and 100% reconfigurable.
There are 16 patented 1-dimensional tensor processors per tile which can be connected configurably with our patented programmable interconnect. This approach gives us the efficiency of hard-wired with the adaptability of programmable. We can configure our tensor processors differently for each AI operation for very high utilization.
Compute is done with INT8, INT16 and/or BF16 inputs, with INT40 and BF32 accumulation for very high accuracy.
16 Dense TOPS (INT8)/tile in N5.
eFPGA and programmable interconnect give huge flexibility but you don’t do low level coding: use our Inference Compiler to convert your neural network model to the configuration files to run on InferX.
Hardwire the data path but with reconfigurable connections.