Super fast, accurate, reconfigurable DSP using small silicon area
InferX delivers high DSP performance from small silicon area and is reconfigurable (in microseconds for advanced nodes).
InferX has flexibility similar to a vector processor but with performance near hard-wired ASIC.
InferX is soft IP for the TPUs which are controlled by EFLX eFPGA which is hard IP.
Ask about benchmarks on 40/28/22/16/12/7/6/5/3/18A and for other DSP operators.
InferX for Advanced Nodes
InferX for advanced nodes scales to 10K-100K int16 MACs
Advanced nodes starting from N5 (N5/4/3 and 18A) will have a new version of EFLX with more I/O’s allowing a single EFLX tile to control up to 16 TPUs = 2K MACs.
Shown here is a configuration with one EFLX tile and 16 TPUs = 2K int16 MACs. This is 3.6 mm2 in N5 and can process 8.5Gigasamples/second of Complex Int16 FFTs of any size.
The larger configuration has 8 EFLX tiles and 128 TPUs = 16K int16 MACs. This is 29mm2 in N5 and can process 68 GS/sec of Complex Int16 FFTs of any size.
InferX is very scalable: from 1 TPU to thousands with performance that scales linearly with the number of TPUs.
InferX for Existing EFLX
InferX for existing EFLX scales up to 16 TPUs = 2K int16 MACs
Existing EFLX eFPGA Tiles on 7, 12, 16, 22, 28 and 40nm can control a single InferX TPU, 4 TPUs or up to 16 TPUs.
Because a single TPU has >3x more MACs than an EFLX DSP tile and can clock faster, a single EFLX tile with a single TPU has the DSP throughput of >>10 EFLX DSP tiles: 125 Megasamples/second of INT16 Complex FFT in GF12 and 200 MS/sec in N16.
The 16 TPU configuration shown has the DSP performance of >100 EFLX DSP tiles: 2 GigaSamples/second of INT16 Complex FFT in GF12 and 3.4GS/sec in N16.
InferX TPU Architecture
InferX TPU Architecture
The InferX TPU consists of a GEMM (matrix/vector) engine, weight memory and NLINX.
Weight memory holds the coefficients for the DSP operation.
EFLX eFPGA controls execution and reorders input/output data.
NLINX applies scaling/bias/quantization; cascades multiple TPUs for larger operations via NLINX chains; and computes complex exponentials, logarithms, etc.
Everything is pipelined and parallel for very high throughput and utilization.
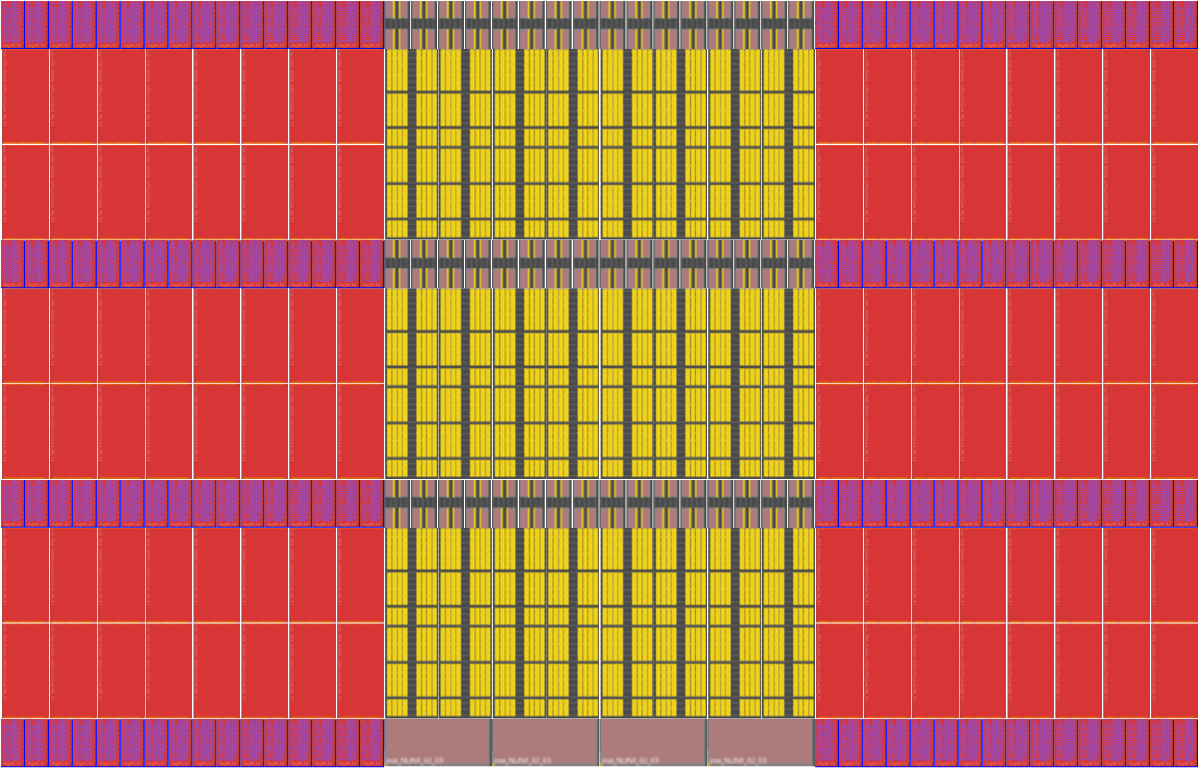
InferX+EFLX Heterogeneous Compute Fabric
InferX+EFLX Heterogeneous Compute Fabric
For applications such as SDR, some functions may better to eFPGA. The InferX array can be supplemented with extra EFLX resources in the center to enable these applications. The internal bandwidth of the EFLX array fabric is Terabytes/second++: ArrayLinx™ mesh interconnect, which connects to the XFLX™ interconnect within each EFLX tile, has 3000 wires per tile in all directions at 1GHz. Here is an example of a Heterogeneous Compute Fabric: