10s of mm2 of InferX in N7/5/3 gives you the performance of Orin AGX in your SoC using a fraction of the DRAM bandwidth.
InferX is a scalable architecture to give the performance you need.
InferX is no-shortcuts Inference that lets you run at very high accuracies while meeting your frame rate and budget.
InferX can run multiple models and reconfigure in a few microseconds for changing workloads.
InferX has the flexibility and the compute to adapt to tough new models over time. Your SoC will need to run models and operators that haven’t been developed yet: this requires maximum flexibility with efficiency = InferX.
You need AI Inference to detect objects ACCURATELY else it’s useless.
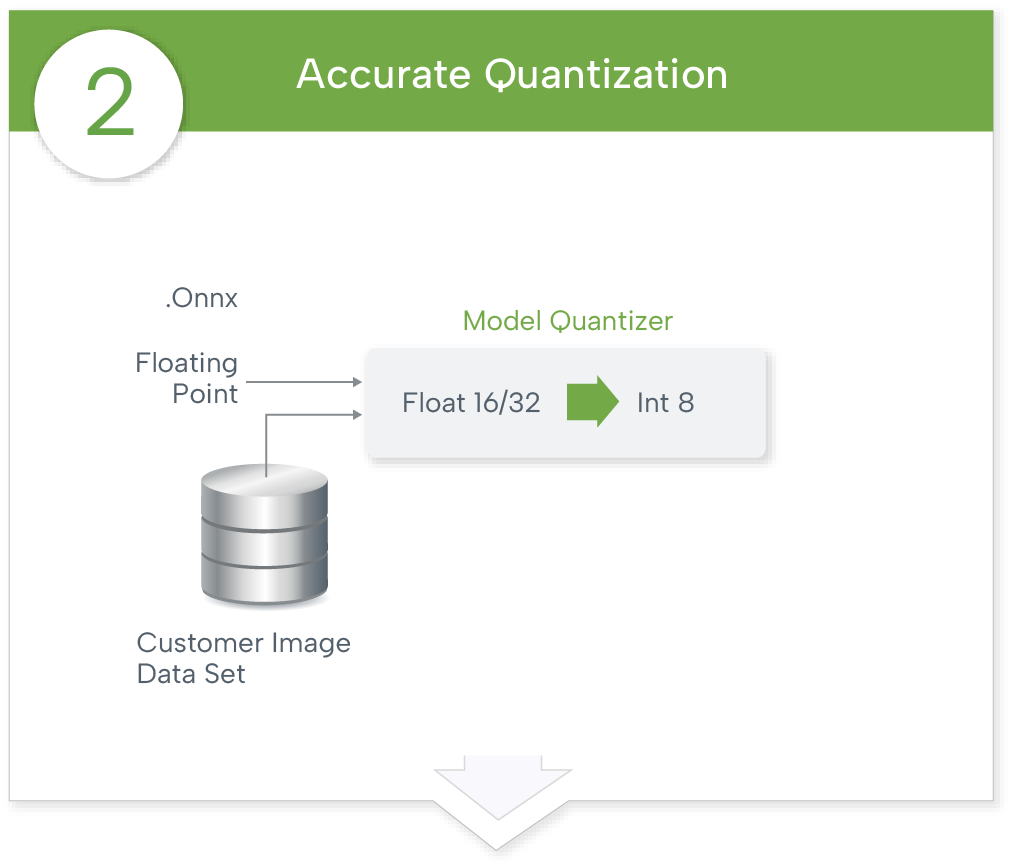
We run most layers in INT8 with INT40 accumulation which provides accuracy almost the same as FP32.
We support mixed precision: for layers that require higher numeric accuracy, such as in Transformer attention heads, we can run INT16 or BF16.
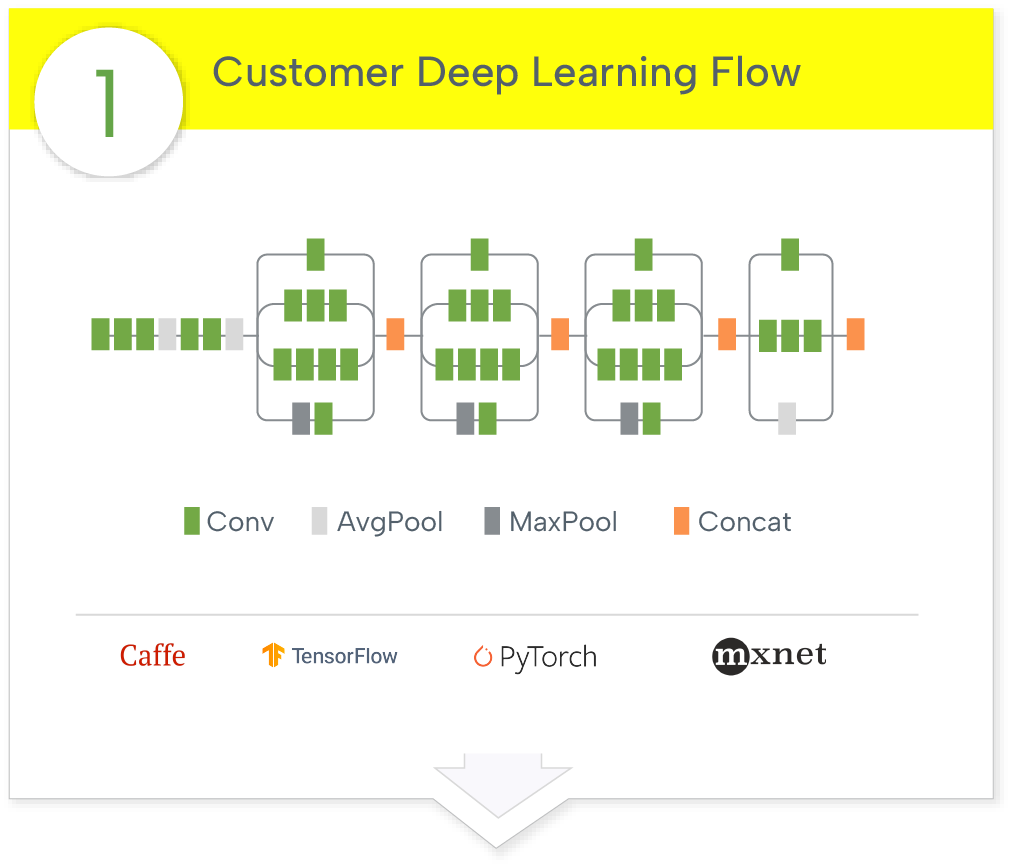
We run the full model with all of the operators without modification.
We do not prune your model or force sparsity – we run your model the way you intended it to run.
Super-Resolution
Super-Resolution Inferencing
InferX enables you to run multi-hundred layer models like Yolov5L6 which process megapixel images (1280×1280) with very high accuracy so you can detect small objects at a distance with very high accuracy AND run 30 frames/second.
This capability is critical for applications such as high speed driving, threat detection, crowd counting and others.
We quantize your models with high accuracy in INT8 for high speed.
All our operators are tested across a wide range of input variations for robustness so you can evolve your models. InferXDK may be evaluated now under NDA and a software evaluation license.
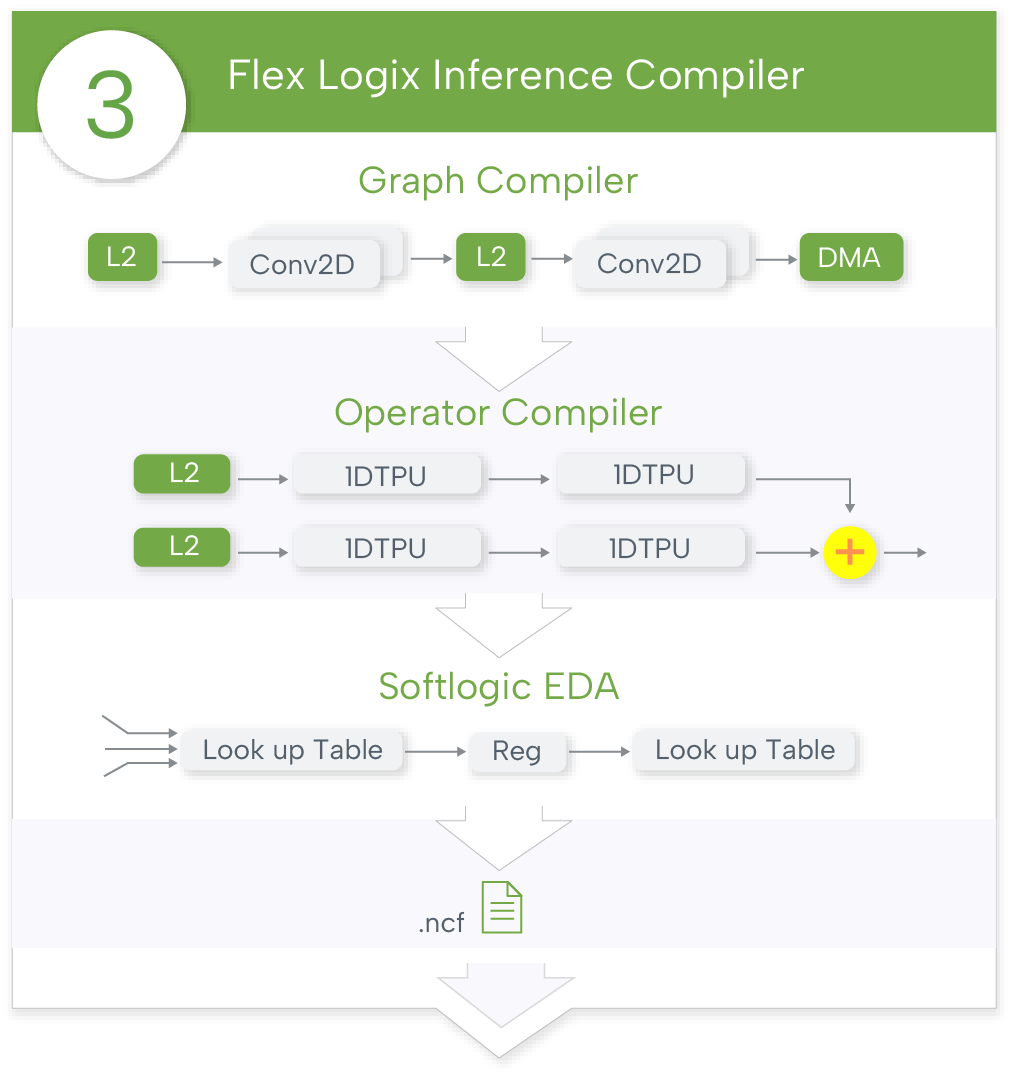
The graph compiler achieves very high utilization. The InferX Compiler has been in use for years.
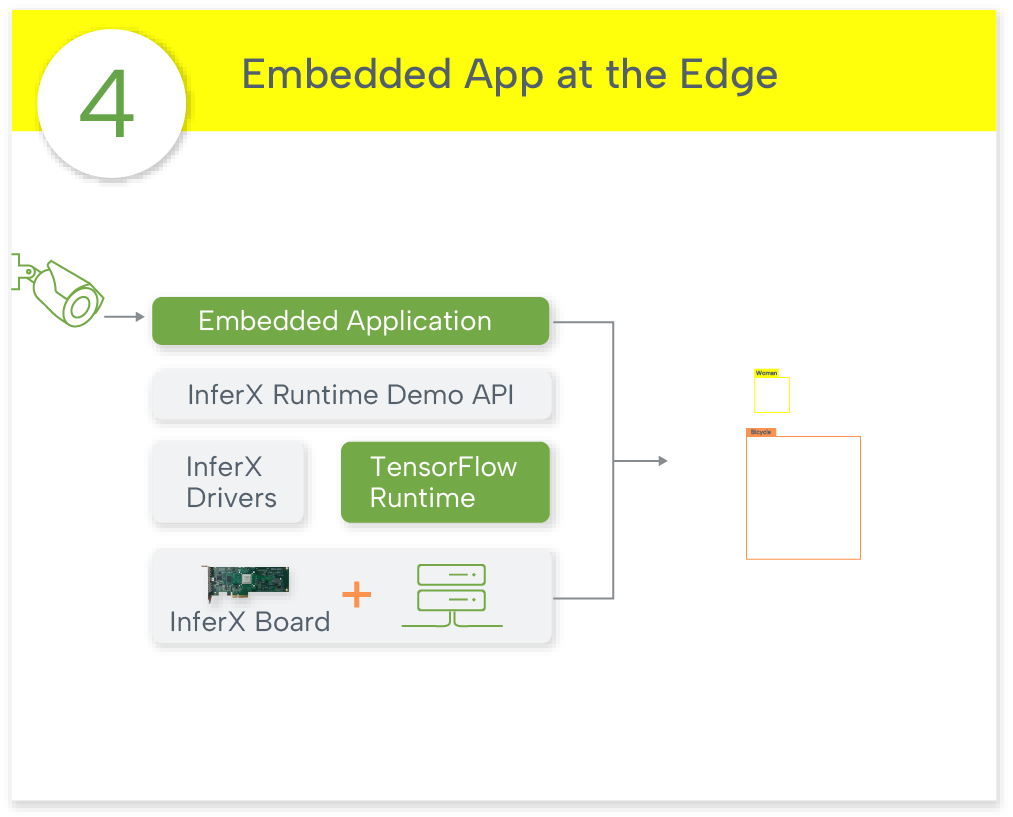
InferX RunTime APIs are simple to ease deployment.
InferX runs at the direction of your SoC: you determine the models to run and the image to run on then give InferX the pointers in memory for inputs and results.